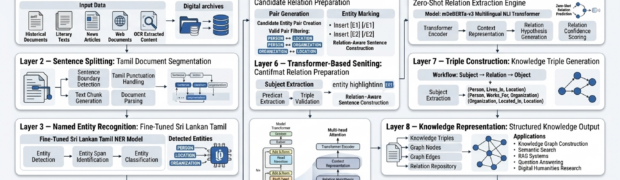
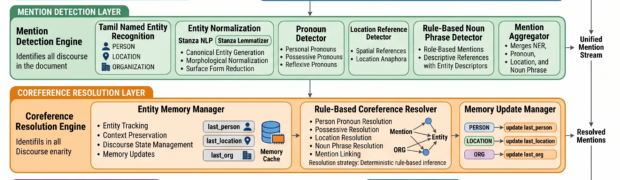
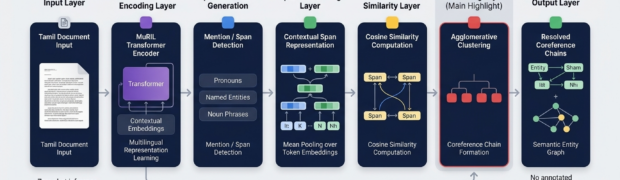
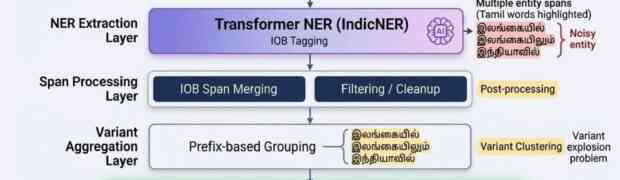
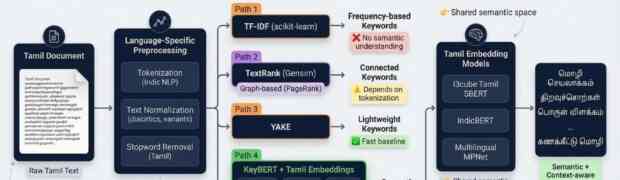
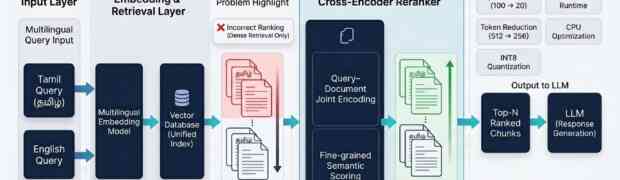
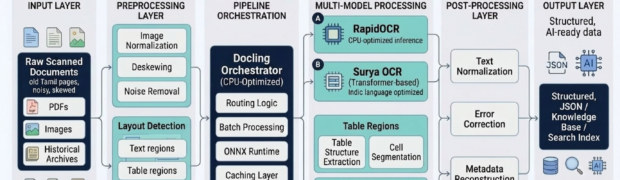
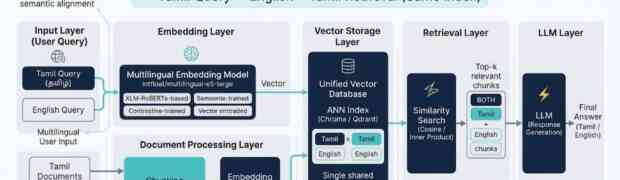
Keyword extraction is a foundational component in modern NLP systems. It directly impacts search quality, indexing efficiency, document summarization, topic discovery, and Retrieval-Augmented Generation (RAG) pipelines. However, for low-resource languages such as Tamil, keyword extraction introduces several challenges that extend beyond simply applying existing algorithms. In practice, achieving reliable extraction required careful system-level engineering involving ...