Named Entity Recognition (NER) is a foundational layer in modern NLP systems. It directly impacts downstream applications such as search, indexing, knowledge graph construction, entity linking, and Retrieval-Augmented Generation (RAG).
However, for Tamil and other morphologically rich languages, entity extraction alone is insufficient. The larger challenge lies in canonicalizing entity variants into stable root forms that can be consistently indexed and linked across documents.
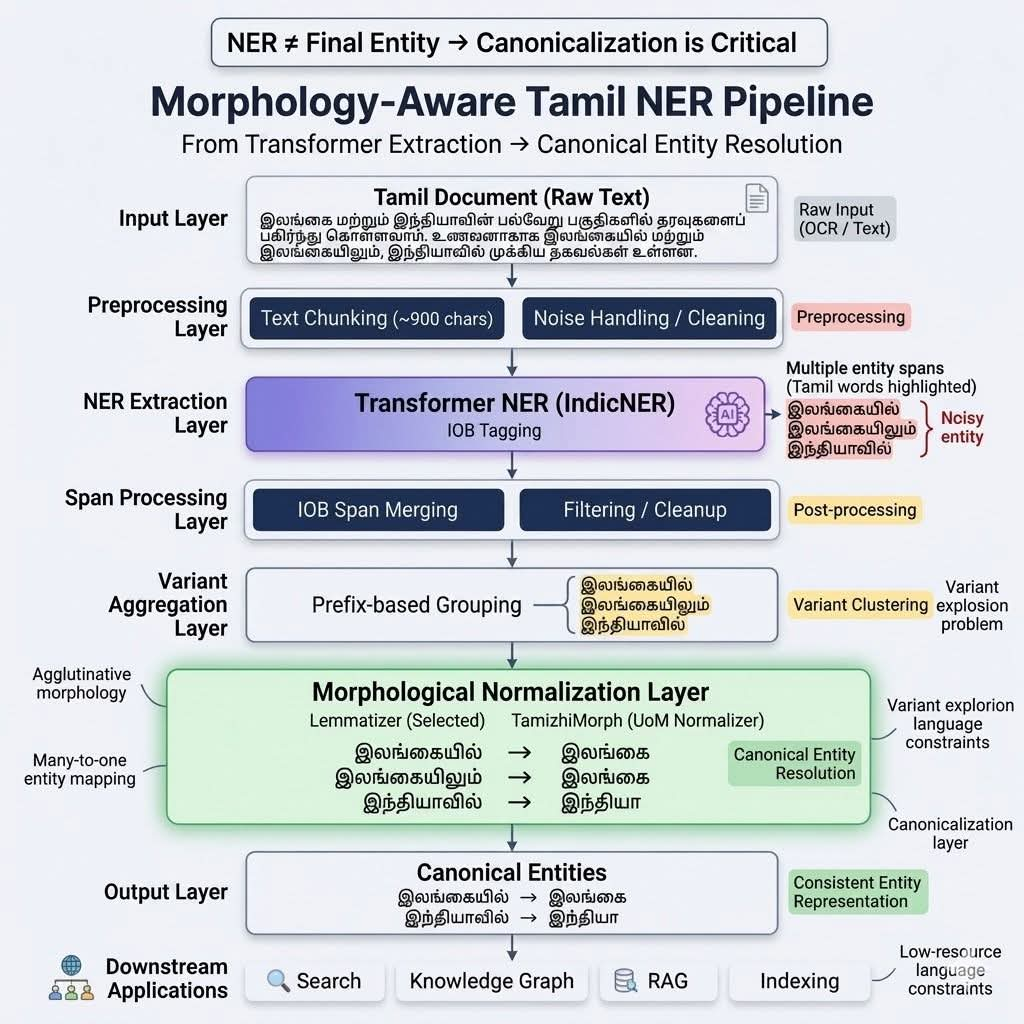
As part of the ongoing Tamil NLP and Noolaham GPT initiatives at CTNLPR, we designed and implemented a morphology-aware Tamil NER pipeline that combines transformer-based extraction with morphological normalization and canonical entity resolution.
Why Tamil NER Is Challenging
Tamil is a highly agglutinative language. A single entity can appear in multiple inflected surface forms depending on grammatical suffixes, case markers, and contextual usage.
For example:
- இலங்கையில்
- இலங்கையிலும்
- இலங்கையிலே
Although all refer to the same canonical entity (“இலங்கை”), transformer-based NER systems typically extract them as separate entities.
This creates several downstream problems:
- Entity duplication
- Inconsistent indexing
- Fragmented knowledge graphs
- Reduced retrieval quality in RAG systems
As a result, canonicalization becomes a critical requirement in Tamil NLP pipelines.
System Architecture
At CTNLPR, we designed a Tamil-aware NER architecture consisting of:
- IndicNER → transformer-based entity extraction
- Custom span merging → IOB tag consolidation
- Prefix-based grouping → heuristic variant clustering
- Morphological normalization layer → canonical entity resolution
The system extends standard transformer-based NER pipelines with language-aware normalization strategies specifically designed for Tamil morphology.
Transformer-Based Entity Extraction
We used IndicNER as the baseline entity extraction model.
Advantages:
- Strong multilingual transformer backbone
- High recall across entity categories
- Effective extraction on noisy multilingual corpora
However, a major limitation became immediately apparent:
Transformer NER models do not enforce canonical forms.
As a result, multiple inflected variants of the same entity were treated as separate entities.
Method Exploration and Evaluation
We evaluated several normalization approaches to resolve this issue.
Prefix-Based Grouping
A lightweight heuristic approach based on shared token prefixes.
Advantages:
- Fast execution
- Simple clustering mechanism
Limitations:
- Not linguistically grounded
- Unstable under complex suffix chains
Although useful as an intermediate clustering layer, it lacked sufficient linguistic robustness.
UoM Thamizhi Morphological Normalizer
We evaluated the morphological normalization approach developed by the University of Moratuwa.
Advantages:
- Linguistically motivated
- Rule-based morphological normalization
However, several practical limitations emerged:
- Reduced robustness on noisy OCR text
- Difficulty handling complex suffix combinations
- Poor generalization to unseen word forms
While theoretically sound, the system struggled under real-world document conditions.
Tamil Lemmatizer (Final Approach)
The strongest results were achieved using a Tamil lemmatization-based normalization layer.
Advantages:
- Consistent root-form extraction
- Better handling of inflected variants
- Improved robustness across document types
- Strong empirical performance under noisy conditions
This became the final canonicalization layer integrated into our production pipeline.
Canonical Entity Resolution
The final architecture performs many-to-one normalization:
| Surface Form | Canonical Entity |
|---|---|
| இலங்கையில் | இலங்கை |
| இலங்கையிலும் | இலங்கை |
| இந்தியாவில் | இந்தியா |
This canonical mapping layer significantly improved consistency across downstream NLP systems.
Pipeline Design
The final production pipeline operates as follows:
- Document ingestion and chunking
- Transformer inference using IndicNER
- IOB span merging and filtering
- Prefix-based variant aggregation
- Morphological normalization (lemmatization layer)
- Canonical entity re-indexing
This hybrid architecture combines transformer-based recall with morphology-aware normalization.
System-Level Challenges
Several engineering challenges emerged during implementation:
Agglutinative Morphology
Tamil suffix chains can become extremely complex, making direct canonicalization difficult without normalization.
Variant Explosion
A single entity appearing across multiple grammatical forms produced fragmented entity representations across documents.
OCR and Noisy Input
Historical and scanned documents introduced spelling inconsistencies and OCR artifacts, reducing normalization stability.
Cross-Document Consistency
Canonical entity representation had to remain stable across multi-document pipelines to support reliable indexing and retrieval.
Observations and Results
Across experiments, several patterns became clear:
- Transformer NER → high recall, weak canonical consistency
- Prefix grouping → useful heuristic but linguistically limited
- UoM normalizer → theoretically strong but operationally fragile
- Lemmatization → strongest practical normalization performance
The final production system combined: IndicNER + Morphological Lemmatization
to achieve robust multilingual entity extraction and canonicalization.
Key Insight
One of the most important findings from this work was:
In Tamil NER, the primary challenge is not entity detection — it is morphological normalization.
NER output should not be treated as the final entity representation.
Canonicalization is essential for:
- Indexing
- Entity linking
- Knowledge graph construction
- Retrieval-Augmented Generation (RAG)
- Cross-document semantic consistency
Without normalization, downstream systems become fragmented and unreliable.
System Implementation at CTNLPR
At CTNLPR, this morphology-aware NER architecture was integrated into our broader Tamil NLP infrastructure as part of the ongoing Noolaham GPT initiative.
Our work included:
- Evaluating transformer-based Tamil NER models
- Designing canonical entity resolution pipelines
- Benchmarking normalization strategies
- Integrating morphology-aware lemmatization layers
- Improving cross-document entity consistency
- Optimizing downstream indexing and retrieval performance
The final system now serves as a foundational entity extraction layer for multilingual search, knowledge graphs, and RAG systems being developed at CTNLPR.
Outcome
The final production-ready Tamil NER system:
- Resolves inflected entity variants
- Produces stable canonical entity forms
- Improves downstream retrieval quality
- Supports scalable multi-document processing
- Enables consistent entity-centric indexing and analytics
Most importantly, the system demonstrates that reliable Tamil NER requires both transformer-based extraction and morphology-aware canonicalization.
Conclusion
Building effective NER systems for Tamil requires significantly more than transformer-based entity extraction.
By combining:
- Transformer NER models
- IOB span consolidation
- Morphological normalization
- Canonical entity resolution
we developed a scalable morphology-aware Tamil NER architecture optimized for multilingual NLP systems and large-scale document processing.