Retrieval-Augmented Generation (RAG) systems are highly dependent on retrieval quality. In multilingual environments, the problem becomes significantly more complex because the retrieval layer must operate across languages while maintaining semantic consistency.
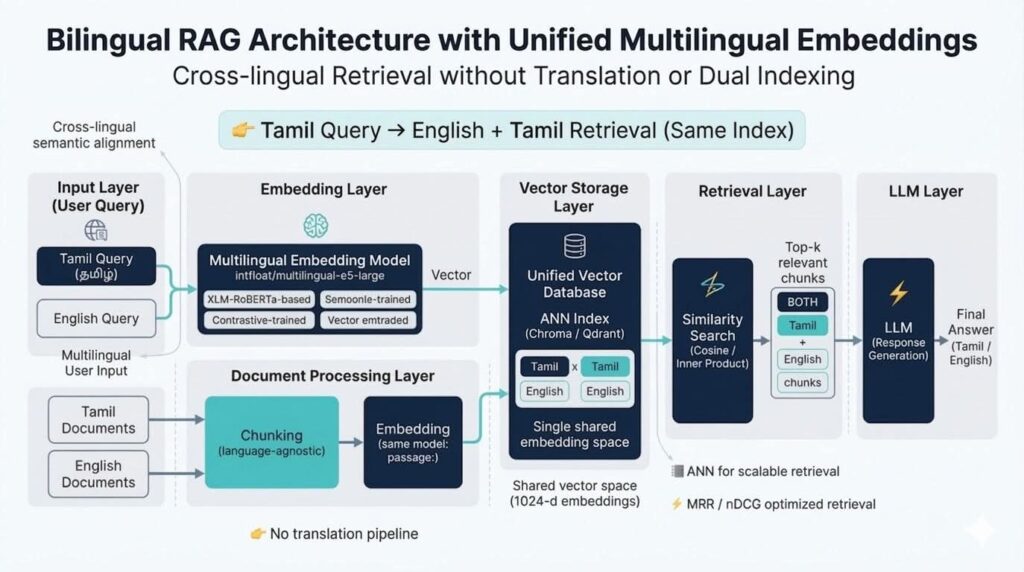
For Tamil–English systems, one of the key challenges is cross-lingual retrieval — enabling a query in Tamil to retrieve semantically relevant Tamil and English passages from a unified index (and vice versa), without relying on translation pipelines or language-specific partitioning.
Cross-Lingual Retrieval in Multilingual RAG
Traditional retrieval systems often assume that the query language and document language are identical. This assumption breaks down in multilingual knowledge systems where relevant information may exist across multiple languages.
To solve this, we rely on multilingual dense embedding models that project Tamil and English text into a shared semantic vector space. Within this space, semantically similar content across languages becomes geometrically aligned, enabling standard vector similarity search to work across languages.
This allows:
- Tamil queries → Tamil + English retrieval
- English queries → Tamil + English retrieval
without maintaining separate retrieval systems.
Core Architecture
The retrieval architecture is based on three principles:
- Unified multilingual embeddings
- Single shared vector index
- Cross-lingual semantic similarity search
The system pipeline consists of:
- Document chunking
- Multilingual embedding generation
- Unified vector indexing
- Approximate nearest neighbor (ANN) retrieval
- LLM-based response synthesis
Model Evaluation
We evaluated several multilingual embedding approaches:
- Sentence Transformers (SBERT variants)
- Indic-specific models (IndicBERT, MuRIL)
During experimentation, several limitations became apparent:
- Weak Tamil–English semantic alignment
- Inconsistent similarity distributions across scripts
- Reduced recall in mixed-language retrieval scenarios
These limitations significantly affected ranking stability and retrieval quality.
Selected Embedding Model
After extensive evaluation, we selected:
→ intfloat/multilingual-e5-large
The model demonstrated significantly stronger cross-lingual retrieval behavior due to several architectural and training characteristics:
- Built on XLM-RoBERTa-large
- Large-scale multilingual pretraining
- Trained with contrastive learning objectives (>1B training pairs)
- Fine-tuned on retrieval benchmarks such as MS MARCO, Mr.TyDi, and MIRACL
- Instruction-aware embeddings using
query:andpassage:prefixes
This resulted in improved semantic alignment between Tamil and English representations, especially for low-resource retrieval tasks.
Unified Indexing Strategy
Instead of maintaining separate indices for each language, we implemented a single unified vector index.
Pipeline:
- Chunk Tamil and English documents
- Generate embeddings using the same multilingual encoder
- Store all vectors in a shared ANN index
This design eliminates language-specific partitioning and simplifies retrieval orchestration.
The final architecture supports:
- Tamil → English retrieval
- English → Tamil retrieval
- Mixed-language retrieval
within the same semantic search space.
Retrieval Flow
The retrieval pipeline operates as follows:
- Encode query (Tamil or English)
- Perform ANN similarity search
- Retrieve top-k semantically relevant chunks
- Pass retrieved context to the LLM for generation
Similarity search is based on dense vector retrieval using cosine similarity.
Benchmark Signals (MRR / nDCG)
Across multilingual benchmarks and internal evaluations, we observed measurable improvements in retrieval quality:
- Higher MRR@10 → improved early precision
- Higher nDCG@10 → better ranking quality
- Improved Recall@10 → stronger multilingual coverage
- More stable similarity distributions across Tamil and English scripts
These improvements were primarily driven by:
- Large-scale contrastive training
- Retrieval-specific fine-tuning
- Better multilingual semantic alignment
Key Insight
A critical realization from this work is that multilingual RAG is not fundamentally a database problem.
It is primarily an embedding alignment problem solved during representation learning.
When both Tamil and English occupy the same semantic vector space:
- Cross-lingual retrieval becomes reliable
- Translation overhead becomes unnecessary
- Retrieval architectures become significantly simpler
Outcome
The final system achieved:
- Stronger cross-lingual ranking quality
- Improved MRR/nDCG performance
- Reduced architectural complexity
- Unified multilingual retrieval
- Better knowledge coverage across languages
Most importantly, the system demonstrates that multilingual retrieval for low-resource languages can be achieved effectively without maintaining separate retrieval pipelines or translation layers.
System Implementation at CTNLPR
At CTNLPR, as part of the ongoing Noolaham GPT initiative, we designed and implemented a bilingual Tamil–English RAG retrieval architecture focused on low-resource multilingual retrieval.
Our work included:
- Evaluating multilingual embedding models for Tamil–English semantic alignment
- Benchmarking retrieval quality using MRR, nDCG, and Recall metrics
- Designing a unified vector indexing strategy without language partitioning
- Implementing ANN-based cross-lingual dense retrieval pipelines
- Optimizing retrieval consistency across Tamil, English, and mixed-language queries
The final system enables:
- Tamil queries retrieving both Tamil and English knowledge
- English queries retrieving Tamil content
- Shared semantic retrieval without explicit translation layers
This architecture now serves as a foundational retrieval layer for downstream Tamil NLP systems, including multilingual RAG, semantic search, and knowledge-centric applications being developed at CTNLPR.
Conclusion
Building multilingual RAG systems for Tamil requires more than multilingual datasets — it requires semantically aligned embeddings capable of supporting reliable cross-lingual retrieval.
By combining:
- Multilingual dense encoders
- Unified vector indexing
- Cross-lingual semantic retrieval
we designed a scalable bilingual RAG architecture capable of retrieving Tamil and English knowledge from a shared semantic space.