The project aims to do large scale annotation, storage and analysis of Sri Lankan Tamil content. This is related to the field of semantic culturomics in which researchers data mine large digital archives to investigate cultural phenomena reflected in language and word usage. It is a form of computational lexicology that studies human behaviour and cultural trends through the quantitative analysis of digitised texts. The underlying data is from Noolaham Foundation, a Digital Archive and a Digital Library undertaking the critical work of documenting, digitally preserving and providing free and open access to knowledge bases and cultural heritage of Sri Lankan Tamil speaking communities. The archive contains digitised text from Sri Lankan newspapers, books, magazines, pamphlets etc from various sources totalling up to approximately 180,000+ documents. It also includes a web archive and born-digital data in text format which would be included in our pipeline.
Goals
The goal of the project is to build an ecosystem that analyses large scale Sri Lankan Tamil content using natural language processing methodologies and generative AI.
Objectives
- Converting digitized content from Noolaham project to text with meta-data tagging. This includes converting newspapers, books, magazines, pamphlets from pdfs and images to text. We do Layout analysis of newspapers, Optical character recognition, Building document type storage, XML conversion of text.
- Building language processing resources using natural language processing resources and building Knowledge engineering capabilities.
- Building a generative AI based tool to query Noolaham’s content, similar to ChatGPT.
The Ecosystem
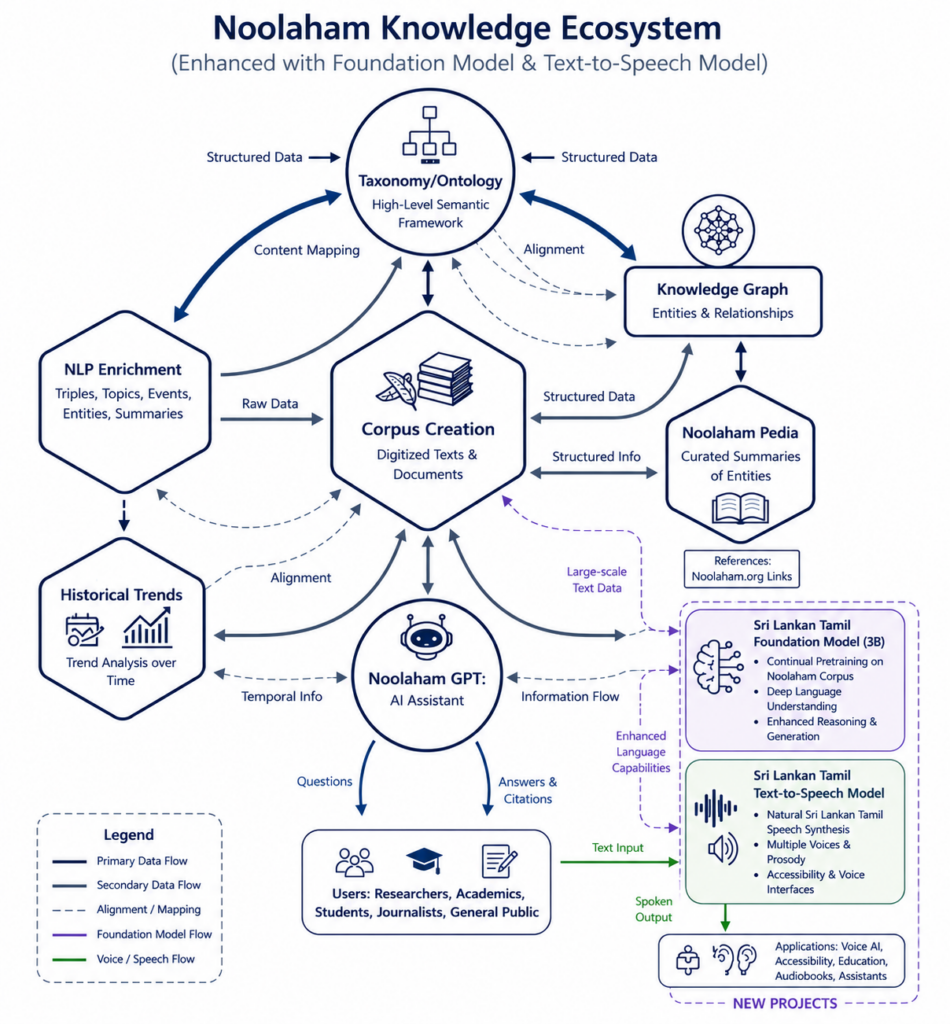
Architecture
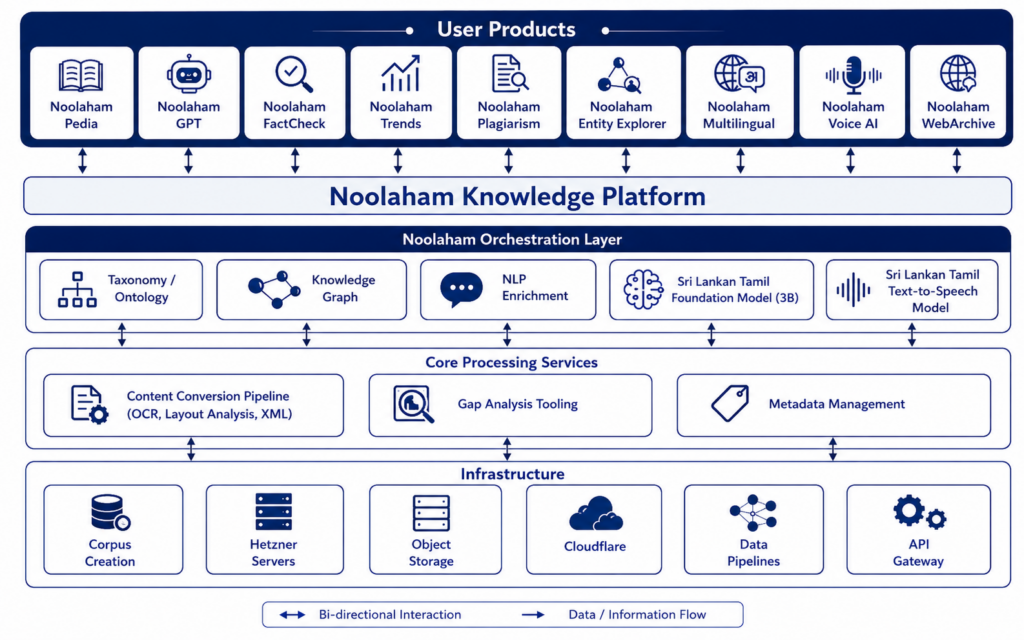
Platform
Development of the digital content conversion pipeline
The platform layer provides the foundational technology infrastructure that powers the entire ecosystem. This includes development of the digital content conversion pipeline that includes document ingestion, optical character recognition (OCR), text extraction, quality enhancement, metadata generation, semantic enrichment, and preparation of large-scale datasets for downstream AI applications.
Custom GPT tool training and core architecture
The platform will also include the development of custom GPT-based tools and domain-specific AI models trained on curated digital content. This involves designing the core AI architecture, developing specialised training pipelines, implementing retrieval-augmented generation (RAG) capabilities, and integrating knowledge sources to enable accurate, context-aware responses.
Projects
Corpus Creation
The authoritative repository of digitized texts and documents produced through upstream ingestion pipelines (OCR, image processing, segmentation, and normalization). It serves as the single source of truth from which all structured, semantic, and temporal knowledge is derived.
NLP Enrichment
An analytical layer that processes corpus content to extract higher-level knowledge such as entities, topics, events, relationships, and summaries. It transforms raw text into structured representations suitable for ontology mapping and downstream knowledge construction.
Taxonomy/Ontology Creation
A high-level semantic framework that defines canonical concepts, classes, and relationships used across the ecosystem. It provides a shared conceptual model to which extracted knowledge is mapped, ensuring consistency, interoperability, and semantic alignment across all components. This will also cover a taxonomy which includes a structured classification system that organizes things into categories and subcategories.
Knowledge Graph
A structured graph of entities and relationships generated from ontology-aligned enriched data. It enables semantic linking, reasoning, inference, and complex queries across people, places, works, events, and concepts represented in the corpus.
A Sri Lankan Tamil Foundation Model
This project aims to build a Sri Lankan Tamil foundation model using large-scale Tamil text from archives, literature, newspapers, and digital content. The goal is to create an AI system that understands the linguistic and cultural nuances of Sri Lankan Tamil, enabling applications such as semantic search, knowledge retrieval, translation, digital preservation, and conversational AI while making Tamil knowledge more accessible for future generations.
A Sri Lankan Tamil Text-to-Speech Model
This project focuses on developing a Sri Lankan Tamil text-to-speech model capable of generating natural and regionally accurate Tamil speech. The goal is to support applications such as voice assistants, accessibility tools, educational platforms, audiobook generation, and spoken conversational AI tailored to Sri Lankan Tamil speakers.
Research
TamilSpanCoref: A SpanBERT-Style End-to-End Neural Coreference Resolution Toolkit for Tamil
High-resource languages such as English have benefited from end-to-end neural spanranking models and SpanBERT-based encoders, but Tamil coreference resolution remains underdeveloped because of limited annotated corpora, agglutinative morphology, case-marked noun phrases, honorific pronouns, flexible word order, split antecedents, noun-noun anaphora, and zero-pronoun phenomena. This research looks into building this capability.
TamilOpenIE: Tamil-Specific Open Information Extraction Using Morphology-Aware Phrase Structures and Dependency-Guided Triple Generation
This research proposes TamilOpenIE, a morphology- and dependency-guided Open Information Extraction framework specifically designed for Tamil text. Inspired by the IndIE architecture, the proposed framework adopts the general idea of phrase-level dependency representation and rule-guided triple generation, but introduces Tamil-specific modifications at the preprocessing, representation, and extraction stages.
TamilMorphTok: A Morphology-Aware LLM Tokenizer for Efficient Tamil Language Model Pretraining
This project proposes TamilMorphTok, a Tamil morphology-aware tokenizer designed specifically for Tamil LLM development. The tokenizer will combine BPE or Unigram subword learning with Tamil morpheme boundary constraints, grapheme-aware pre-tokenization, sandhi/punarchi-aware splitting, byte fallback for unseen characters, and reversible detokenization. Unlike plain BPE, which may split Tamil words based only on frequency, TamilMorphTok will aim to preserve linguistically meaningful Tamil units while still remaining efficient for neural language modeling.
TamilPredNorm: Neural-Hybrid Predicate Canonicalization for Tamil Triple Extraction and Knowledge Graph Construction
This project proposes TamilPredNorm, a neural-hybrid predicate canonicalization framework for Tamil. The system will combine Tamil morphological analysis, compound verb segmentation, light-verb detection, noun-verb predicate mapping, contextual transformer representations, and relation-aware canonicalization to convert Tamil surface predicates into normalized relation labels. The proposed framework will produce both a canonical predicate and structured grammatical metadata such as tense, aspect, polarity, modality, voice, honorificity, and light-verb contribution.
TamilTopicX: A Morphology-Aware Transformer-Based Topic Modeling Framework for Tamil Text Analytics
This research proposes TamilTopicX, a morphology-aware transformer-based topic modeling framework for Tamil. The framework will combine Tamil text normalization, stopword and suffix-aware preprocessing, optional lemmatization or stem normalization, transformer-based document embeddings, clustering based topic discovery, phrase-aware c-TF-IDF topic representation, and Tamil topic-label generation.
A Hierarchical linguistic representation encoder for transformer-based tamil language modelling
Transformer-based language models have become the dominant foundation for modern natural language processing. However, their standard input pipeline often depends on statistical tokenization and learned token embeddings that may not sufficiently represent the internal structure of morphologically rich and agglutinative languages. The research will examine whether linguistically guided representation learning can improve Tamil language modeling and downstream NLP performance while providing a more general architectural direction for morphologically rich languages.
Products
Noolaham GPT
An AI-powered assistant that provides interactive question answering, exploration, and synthesis over the Noolaham ecosystem. It draws on corpus content, enriched structures, ontology, and the knowledge graph to deliver contextual answers with citations and temporal awareness.
Noolaham WebArchive
Noolaham WebArchive enables the ingestion, preservation, and analysis of born-digital Tamil web content such as blogs, online news portals, and community forums, preventing digital loss. Archived data is processed through the same NLP enrichment pipeline as digitized texts, allowing unified indexing, metadata tagging, and semantic linking within the Noolaham Knowledge Graph.
Noolaham Entity Explorer
Noolaham Entity Explorer is an AI-powered knowledge exploration platform designed to identify, organize, and connect entities such as people, places, organizations, events, and concepts from Sri Lankan Tamil archival and digital content. Using ontology-aware retrieval and semantic search, the system enables users to explore relationships across historical documents, literature, newspapers, and cultural records, making Tamil knowledge more searchable, discoverable, and accessible for research, education, and digital preservation.
Noolaham Trends
The system detects shifts in discourse related to political movements, migration, education, social reforms, literature, religion, and identity formation using topic modelling, named entity frequency tracking, sentiment analysis, and event co-occurrence mapping. These insights are presented through interactive dashboards that enable researchers to explore long-term trends in terminology, ideological narratives, cultural practices, and community concerns across decades of archived newspapers, books, and born-digital content.
Noolaham MultiLingual
Noolaham MultiLingual is a cross-lingual access and translation layer that enhances the discoverability of Tamil heritage content for global audiences. Using neural machine translation and multilingual embeddings, it enables bidirectional translation and supports cross-lingual information retrieval while maintaining semantic fidelity.
Noolaham Pedia
A curated knowledge presentation layer that generates human-readable summaries of entities and concepts. It organizes information derived from the knowledge graph and corpus into accessible entries, with transparent references back to original Noolaham sources.
Noolaham Voice AI
Noolaham Voice AI is a multilingual AI-powered voice platform that enables natural Tamil voice interactions, speech-based search, conversational AI assistance, and audio access to digital knowledge, archives, and educational content through advanced speech recognition and text-to-speech technologies.
Noolaham Plagarism
Noolaham Plagiarism is an AI-powered system for detecting textual similarity and verifying document provenance in low-resource Tamil corpora, identifying direct copying, paraphrasing, translation plagiarism, and content reuse using semantic and stylometric analysis.
Noolaham FactCheck
Noolaham FactCheck is an automated claim verification system that cross-references statements from digitized documents against trusted archival sources within the Noolaham ecosystem. Using named entity recognition, event extraction, and knowledge graph-based reasoning, it evaluates claims related to historical events, public figures, institutions, and socio-political developments with contextual evidence from primary sources.
Conclusion
As part of the language preprocessing layer of the ecosystem we have completed the development of the digital content conversion pipeline. As next steps layout analysis, ocr and xml conversion has to be run on the whole of Noolaham’s content to convert it to raw text. This requires significant resources and budget related to server cost and running time. I will submit a separate proposal specifying those requirements. Separate efforts have to be initiated to build the processing resources layer and the knowledge engineering layer.