Coreference Resolution (CR) is one of the most important tasks in Natural Language Processing (NLP). It focuses on identifying whether multiple expressions within a document refer to the same real-world entity.
Resolving these semantic references is critical for document-level understanding and directly impacts downstream NLP systems such as:
- Information Extraction
- Knowledge Graph Construction
- Question Answering
- Relation Extraction
- Semantic Search
- Conversational AI
- Retrieval-Augmented Generation (RAG)
While English NLP already has mature coreference systems and libraries, Tamil remains a highly challenging low-resource language for discourse-level semantic modeling.
As part of ongoing Tamil NLP research at CTNLPR, we explored how modern multilingual coreference architectures can be adapted for low-resource Tamil language understanding.
Why Tamil Coreference Resolution Is Challenging
Most existing coreference systems are heavily optimized for English. Architectures such as:
- spaCy-based pipelines
- NeuralCoref
- AllenNLP coreference models
- Transformer-based antecedent ranking systems
rely on assumptions and linguistic patterns that do not transfer cleanly to Tamil.
Tamil introduces several structural and linguistic complexities:
- Agglutinative morphology
- Free word order
- Pronoun dropping
- Implicit subject references
- Rich inflectional structures
- Long-distance discourse dependencies
- Noun-to-noun semantic references
These characteristics make direct adaptation of English-centric architectures highly unreliable.
Low-Resource Constraints
Another major challenge is the lack of Tamil-specific resources.
Currently:
- No dedicated Tamil coreference libraries exist publicly
- No production-ready Tamil CR models are available
- Large annotated Tamil coreference corpora are unavailable
- Most multilingual systems remain heavily English-biased
This makes supervised transformer training approaches difficult to scale for Tamil.
Limitations of Traditional Supervised Approaches
Many multilingual coreference systems rely on supervised transformer architectures combined with linguistic feature engineering.
These systems often incorporate features such as:
- Entity type
- Word category
- Number agreement
- Gender agreement
- Antecedent indicators
Although effective for high-resource languages, these approaches depend heavily on:
- Manually annotated datasets
- Task-specific supervision
- Expensive training pipelines
- Large computational resources
For Tamil, the absence of benchmark-scale annotated corpora becomes a critical bottleneck.
A Different Direction: Zero-Shot Contextual Modeling
After extensive research and evaluation, we identified that zero-shot multilingual contextual modeling provides a more scalable direction for Tamil coreference resolution.
Instead of relying on supervised antecedent ranking architectures, the CTNLPR approach focuses on:
- Contextual span modeling
- Semantic similarity learning
- Unsupervised clustering
- Multilingual transformer representations
This reduces dependency on large annotated datasets while still leveraging strong contextual semantic understanding.
System Architecture
The architecture currently being explored at CTNLPR consists of:
- MuRIL-based contextual embeddings
- Span-based mention detection
- Contextual span representations
- Cosine similarity-based semantic linking
- Agglomerative clustering
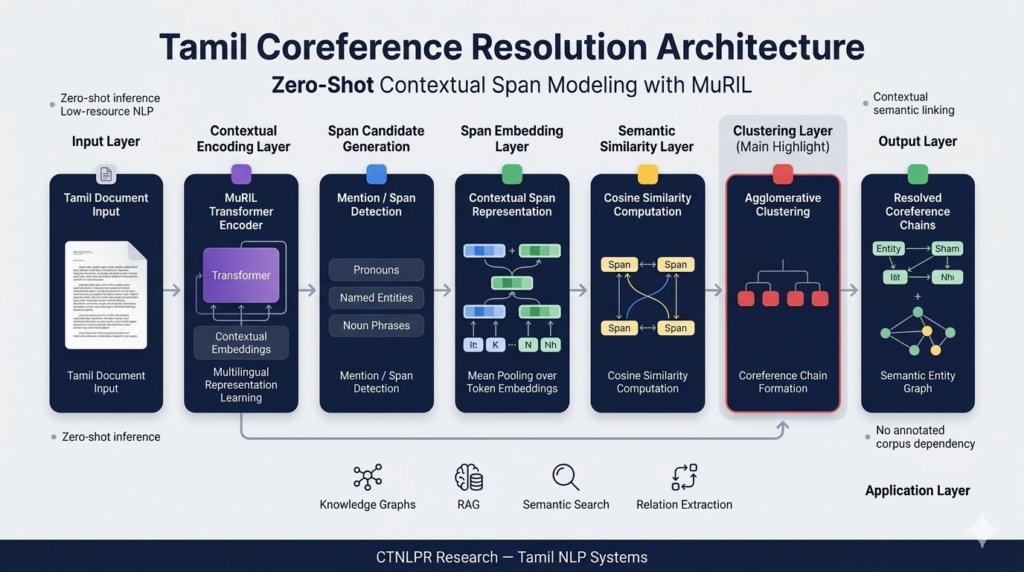
MuRIL-Based Contextual Encoding
The system uses MuRIL as the contextual encoder.
MuRIL is particularly suitable because it was pretrained specifically for Indian languages and multilingual semantic understanding.
The encoder generates contextual token embeddings that capture:
- Semantic context
- Syntactic dependencies
- Cross-sentence relationships
- Multilingual language patterns
This provides a stronger foundation for Tamil discourse modeling compared to English-centric multilingual models.
Span Candidate Generation
Instead of manually defining antecedents, the system automatically generates candidate spans from Tamil text.
These spans may represent:
- Pronouns
- Named entities
- Noun phrases
- Semantic references
This span-based strategy allows the architecture to remain flexible and language-independent.
Contextual Span Representation
Once candidate spans are generated, contextual span embeddings are constructed using token-level representations from MuRIL.
The system applies:
- Mean pooling over token embeddings
- Span-level semantic encoding
- Context-aware representation construction
This enables semantically similar mentions to occupy nearby regions within the embedding space.
Semantic Similarity and Clustering
After span representation construction, the system performs:
- Heuristic span pruning
- Cosine similarity computation
- Similarity-driven clustering
Agglomerative clustering is then used to group semantically related mentions into discourse-level entity chains.
This removes the need for explicit antecedent ranking while still enabling coherent coreference grouping.
Why This Approach Works Well for Tamil
This direction is particularly effective for Tamil because it avoids dependency on large manually annotated datasets while leveraging multilingual contextual knowledge learned during transformer pretraining.
Key advantages include:
- Zero-shot learning capability
- Scalability for low-resource environments
- Reduced annotation dependency
- Contextual semantic understanding
- Better adaptation to Tamil morphology
- Lightweight unsupervised inference
This makes the architecture more practical for real-world Tamil NLP deployment scenarios.
Key Insight
One of the most important findings from this research is:
Coreference resolution for Tamil is not primarily a rule-engineering problem — it is a contextual semantic modeling problem.
Strong discourse understanding requires:
- Context-aware embeddings
- Span-level semantic reasoning
- Cross-sentence entity linking
- Language-aware discourse modeling
Without these components, downstream systems struggle to maintain semantic consistency across documents.
System Implementation at CTNLPR
At CTNLPR, we are actively exploring and prototyping this zero-shot multilingual coreference architecture as part of the ongoing Noolaham GPT initiative.
Our work currently includes:
- Researching multilingual CR architectures for Tamil
- Evaluating MuRIL-based contextual encoding
- Designing span-based semantic linking pipelines
- Exploring unsupervised clustering strategies
- Building scalable low-resource discourse understanding systems
The long-term objective is to develop production-grade Tamil discourse understanding infrastructure for multilingual AI systems.
Conclusion
Building effective Tamil coreference resolution systems requires significantly more than adapting English NLP pipelines.
By combining:
- Multilingual contextual transformers
- Span-based semantic representations
- Similarity-driven clustering
- Zero-shot multilingual inference
we are developing a scalable architecture for document-level semantic understanding in Tamil.
This work represents an important step toward building modern, context-aware Tamil NLP systems for real-world low-resource AI applications.