Keyword extraction is a foundational component in modern NLP systems. It directly impacts search quality, indexing efficiency, document summarization, topic discovery, and Retrieval-Augmented Generation (RAG) pipelines.
However, for low-resource languages such as Tamil, keyword extraction introduces several challenges that extend beyond simply applying existing algorithms. In practice, achieving reliable extraction required careful system-level engineering involving preprocessing, tokenization, normalization, and multilingual semantic modeling.
As part of the ongoing Noolaham GPT initiative at CTNLPR, we designed and implemented a Tamil-aware keyword extraction pipeline that combines statistical methods, graph-based ranking, and embedding-based semantic extraction.
Why Keyword Extraction Is Challenging for Tamil
Many existing keyword extraction libraries are primarily designed for English and other high-resource languages. Tamil introduces additional complexities:
- Agglutinative morphology
- Spelling and orthographic variations
- Limited language-specific NLP tooling
- Inconsistent tokenization behavior
- Lack of native Tamil stopword integration
As a result, directly applying standard extraction libraries often produces noisy or semantically weak keywords.
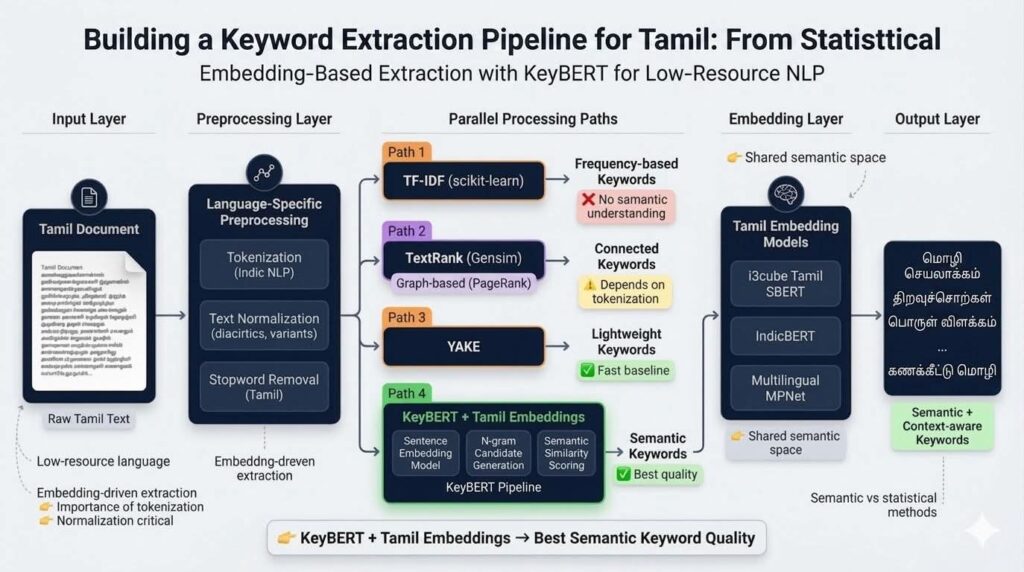
System Architecture
Our pipeline integrates multiple extraction strategies:
- scikit-learn → TF-IDF-based statistical extraction
- Gensim → TextRank graph-based ranking
- KeyBERT → embedding-based semantic extraction
To support Tamil processing, we integrated Indic NLP preprocessing techniques, including:
- Tokenization
- Text normalization
- Stopword filtering
- Diacritic handling
This preprocessing layer was critical for stabilizing downstream extraction quality.
Method Evaluation
We evaluated multiple extraction approaches to understand their strengths and limitations under Tamil NLP conditions.
TF-IDF
TF-IDF provided a strong statistical baseline for identifying globally important terms across corpora.
Advantages:
- Lightweight
- Fast computation
- Effective for corpus-level frequency analysis
Limitations:
- No semantic understanding
- Frequency-driven ranking only
TextRank
TextRank adapts the PageRank algorithm to textual data by constructing graph relationships between words.
Advantages:
- Unsupervised
- No training required
Limitations:
- Highly sensitive to tokenization quality
- Graph instability under noisy Tamil segmentation
YAKE
YAKE performed well as a lightweight per-document keyword extraction baseline.
Advantages:
- Fast inference
- No external models required
- Reliable for smaller documents
However, semantic understanding remained limited.
Embedding-Based Extraction with KeyBERT
The strongest results were achieved using KeyBERT combined with Tamil-capable embedding models.
A critical realization during experimentation was: KeyBERT itself is not language-aware. Its effectiveness depends entirely on the embedding model.
Using default English embeddings produced poor semantic extraction quality for Tamil documents. Replacing them with Tamil and multilingual Indic embedding models dramatically improved performance.
Embedding Models Evaluated
We integrated several multilingual and Tamil-specific embedding models:
- l3cube-pune/tamil-sentence-bert-nli
- ai4bharat/indic-bert
- paraphrase-multilingual-mpnet-base-v2
The extraction pipeline operates as follows:
- Document embedding generation
- Candidate n-gram extraction
- Semantic similarity computation
- Relevance-based ranking
This allowed semantically meaningful phrases to be identified even when they were not frequency-dominant.
System-Level Challenges
Several engineering challenges emerged during implementation:
Tamil Stopword Handling
Tamil stopwords are not automatically supported in most libraries. We implemented custom stopword filtering layers to improve extraction precision.
Text Normalization
Tamil text frequently contains:
- Orthographic variations
- Diacritic inconsistencies
- OCR-induced noise
Normalization significantly improved embedding consistency and keyword quality.
Tokenization Stability
Graph-based and embedding-based extraction methods were highly sensitive to tokenization behavior. Consistent segmentation became essential for reliable extraction.
Observations and Results
Across experiments, several patterns became clear:
- TF-IDF → effective for corpus-level topic signals
- YAKE → strong lightweight baseline
- TextRank → unstable under noisy tokenization
- KeyBERT + Tamil embeddings → strongest semantic keyword quality
The final embedding-based pipeline consistently produced more contextually meaningful keywords compared to purely statistical methods.
Key Insight
One of the most important findings from this work was:
In Tamil NLP, keyword extraction is not constrained primarily by the extraction algorithm itself.
The dominant factors are:
- Embedding quality
- Tokenization consistency
- Text normalization quality
Without solving these foundational issues, even advanced extraction algorithms produce weak results.
System Implementation at CTNLPR
At CTNLPR, this keyword extraction pipeline was integrated into the broader Noolaham GPT ecosystem as part of our multilingual NLP infrastructure.
Our work included:
- Evaluating extraction algorithms for Tamil corpora
- Integrating Tamil-aware preprocessing pipelines
- Benchmarking embedding models for semantic extraction
- Building embedding-based keyword ranking systems
- Optimizing extraction quality for downstream RAG and search pipelines
The final system now supports semantically meaningful keyword extraction across multilingual document collections.
Outcome
The final production pipeline:
- Produces semantically relevant Tamil keywords
- Handles multilingual document collections
- Integrates into downstream search and RAG systems
- Supports scalable NLP workflows for low-resource languages
Most importantly, the work demonstrates that high-quality keyword extraction for Tamil is achievable when embedding quality and language-specific preprocessing are treated as first-class system components.
Conclusion
Keyword extraction for low-resource languages requires significantly more than applying standard NLP libraries out of the box.
By combining:
- Statistical extraction methods
- Graph-based ranking
- Embedding-driven semantic extraction
- Tamil-aware preprocessing pipelines
we developed a scalable keyword extraction system optimized for Tamil NLP applications and multilingual retrieval systems.