Document extraction is often straightforward at demo scale. However, under real production conditions—large document volumes, multilingual corpora, and limited hardware resources—the problem becomes significantly more complex.
Modern Document AI systems must optimize not only for accuracy, but also for scalability, latency, infrastructure cost, and multilingual robustness.
Constraint 1: Cost (Operational Expenditure)
Cloud-based OCR and parsing systems such as Google Cloud Vision and LLM-driven document parsers dramatically simplify development and experimentation. However, these systems introduce a linear operational cost model:
- Cost increases proportionally with document volume
- Every inference depends on external API calls
- Pipelines incur continuous recurring expenses
At small scale, these costs may appear manageable. At production scale—especially for large archival digitization projects involving millions of pages—the operational overhead becomes economically unsustainable.
As a result, real-world document processing systems cannot rely exclusively on API-driven architectures.
Constraint 2: Hardware-Aware Inference
When shifting toward open-source OCR and document understanding models, the bottleneck moves from API cost to infrastructure efficiency.
GPU-based deployments provide high throughput, but scaling GPU infrastructure introduces significant capital and operational expense. CPU-based deployments are considerably more affordable, but require extensive optimization in order to remain practical.
This introduces several engineering requirements:
- Model optimization techniques (quantization, pruning)
- Optimized inference runtimes such as ONNX Runtime and OpenVINO
- Efficient pipeline orchestration and batching strategies
Under these constraints, the objective is no longer “maximum accuracy at any cost.” Instead, the challenge becomes:
Optimizing accuracy, latency, and throughput simultaneously under CPU constraints.
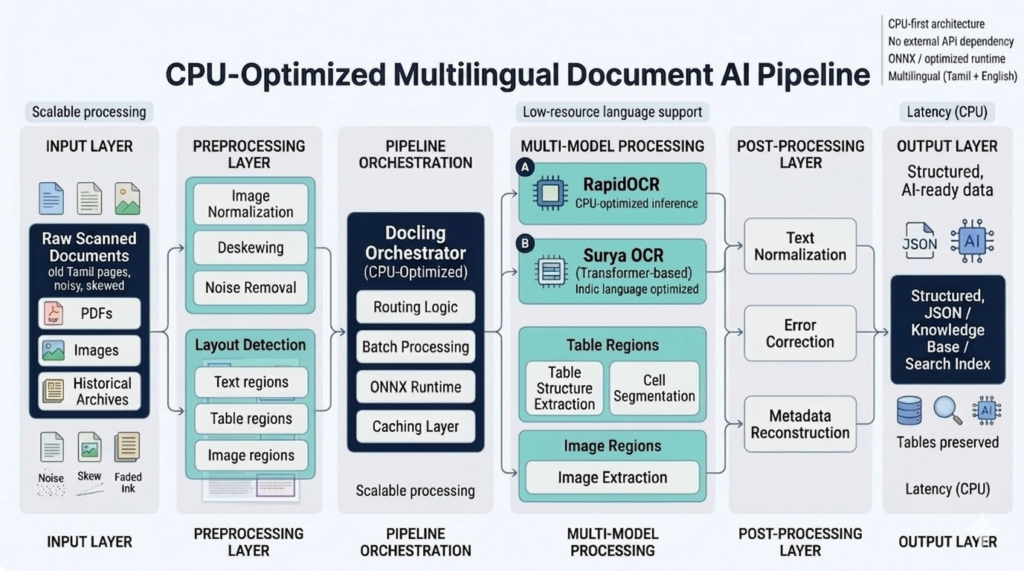
Document AI Is a Pipeline Problem
A common misconception is that Document AI can be solved using a single OCR model. In practice, production systems are composed of multiple tightly coupled stages:
- Layout detection and reading-order analysis
- Region segmentation (text, tables, images)
- Table structure reconstruction
- Text detection and recognition
- Structural parsing and metadata extraction
Overall system performance depends not only on model quality, but also on orchestration efficiency between these stages. In many deployments, the slowest pipeline component determines total throughput.
Language Constraints in Low-Resource Settings
Extending Document AI systems beyond English introduces another layer of complexity, particularly for low-resource languages such as Tamil.
Several limitations become immediately apparent:
- Limited OCR support for Tamil scripts
- Weak handling of agglutinative morphology and complex ligatures
- Lack of CPU-optimized multilingual models
- Poor layout and table generalization across Indic documents
As a result, many pipelines that perform well on English documents degrade significantly in multilingual production environments.
Our Focus at CTNLPR (Noolaham Corpus)
At CTNLPR, through the Noolaham corpus initiative, we are building a CPU-first multilingual document intelligence pipeline focused on scalable, production-grade processing.
Our current focus includes:
- Tamil + English multilingual support
- Layout-aware extraction for text, tables, and images
- CPU-optimized inference pipelines
- Reduced dependency on external APIs
- Scalable processing for large archival collections
The broader objective is not simply accurate OCR, but sustainable and efficient multilingual document understanding at scale.
Research Direction
The central challenge in production-grade Document AI is not accuracy alone.
The real optimization target is: accuracy × throughput × cost
Balancing these three dimensions is essential for building scalable systems for low-resource languages and large archival corpora.