Retrieval-Augmented Generation (RAG) systems are fundamentally dependent on retrieval quality. In multilingual environments, dense retrieval can surface relevant passages, but retrieval alone is often insufficient for producing reliable downstream responses.
In practice, not all retrieved chunks are equally relevant. Passing large sets of loosely related candidates directly into the LLM increases token usage, introduces noisy context, and degrades overall response quality.
For Tamil–English multilingual systems, this problem becomes significantly more pronounced due to cross-lingual ranking inconsistencies.
The Ranking Problem in Multilingual RAG
Dense retrievers are generally effective at identifying semantically related documents. However, they frequently struggle with ranking precision, especially for mixed-language queries involving Tamil and English.
This creates several downstream issues:
- Relevant documents ranked lower than less relevant passages
- Cross-lingual ranking inconsistencies
- Reduced answer quality during generation
- Increased context noise inside the LLM
As a result, retrieval quality cannot be measured solely by recall. Precise ranking becomes equally critical.
Core Approach
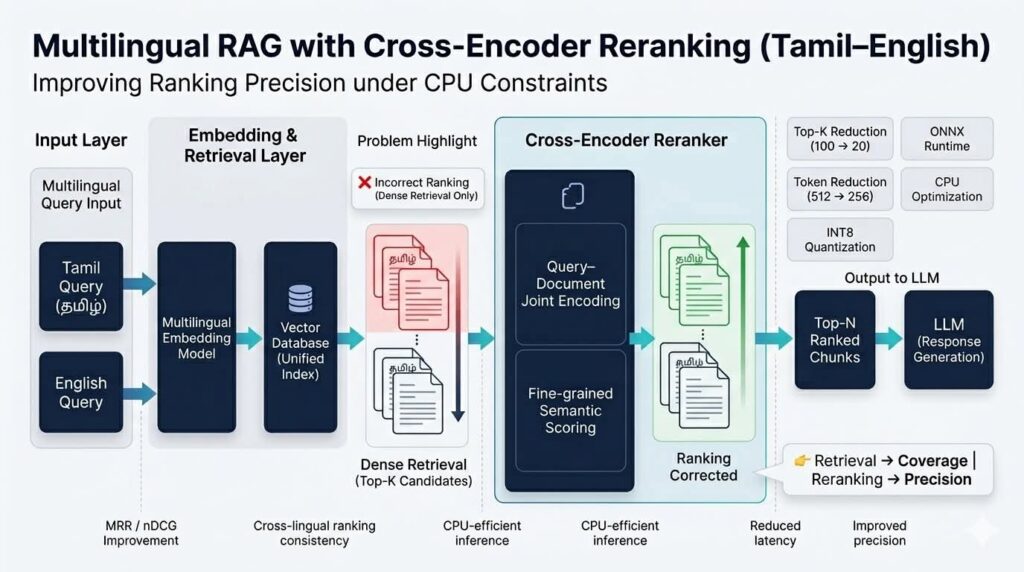
At CTNLPR, we designed and integrated a cross-encoder reranking layer into our Tamil–English RAG pipeline to refine multilingual retrieval results before generation.
Unlike traditional bi-encoder retrieval systems, cross-encoders jointly process the query and candidate document during inference. This allows the reranker to capture fine-grained semantic relationships between the query and retrieved passages.
The reranking layer provides several advantages:
- Joint query–document semantic encoding
- Improved ranking precision
- Better multilingual alignment
- More stable cross-lingual relevance scoring
This enables accurate ordering of multilingual retrieval candidates prior to LLM inference.
Model Evaluation
We evaluated multiple multilingual reranking models under CPU-constrained deployment environments:
- BGE-v2-m3 → strong ranking quality, higher CPU latency
- jina-v3-multi → strong cross-lingual consistency
- jina-v2-cpu-opt → best latency–quality balance
- gte-multilingual → stable multilingual performance
During evaluation, several limitations became apparent when reranking was absent:
- Correct documents retrieved but incorrectly ordered
- Ranking instability for mixed-language queries
- Lexical fusion methods (e.g., RRF) introducing cross-script noise
These observations highlighted that multilingual retrieval requires ranking-aware optimization, not retrieval alone.
Two-Stage Retrieval Architecture
The final system uses a two-stage retrieval pipeline:
- Dense retrieval generates Top-K candidate passages
- Cross-encoder reranker evaluates semantic relevance
- Candidate passages are rescored and reordered
- Top-ranked chunks are passed to the LLM
This architecture improves retrieval precision while controlling downstream context size.
CPU Optimization Strategy
Cross-encoder rerankers are computationally expensive, especially in CPU-only environments. Since our deployment environment prioritizes CPU inference efficiency, optimization became a central engineering challenge.
The primary objective was to maximize ranking quality while minimizing inference latency
Candidate Reduction (Highest Impact Optimization)
The largest performance improvement came from reducing reranker workload.
Instead of reranking large candidate sets:
- Top-K was reduced aggressively (e.g., 100 → 20)
- Forward-pass count was minimized
- Overall latency dropped significantly
This reduced unnecessary reranker computation while preserving ranking quality.
ONNX Runtime + INT8 Quantization
To improve CPU inference efficiency, we optimized reranker deployment using:
- PyTorch → ONNX conversion
- INT8 dynamic quantization
This provided several benefits:
- Faster inference latency
- Reduced memory consumption
- Better CPU throughput
- Minimal degradation in ranking quality
The optimized runtime significantly improved practical deployment feasibility for multilingual reranking.
Token and Runtime Optimization
Additional optimizations focused on attention complexity and runtime efficiency:
- Reduced maximum token length (512 → 256)
- Optimized CPU threading (OMP / MKL)
- Efficient tokenization and batching strategies
Since transformer self-attention scales quadratically with sequence length (O(n²)), reducing token length had a major impact on latency reduction.
Performance Signals
Across internal evaluations, the optimized reranking pipeline achieved:
- Latency reduction from seconds → sub-second inference
- Strong multilingual ranking quality (MRR / nDCG maintained)
- Stable Tamil ↔ English ranking consistency
- Improved downstream LLM response quality
The final architecture achieved production-ready CPU inference performance while maintaining strong ranking precision.
What Didn’t Work
Several approaches produced unstable results in multilingual environments:
- Similarity-threshold filtering → inconsistent across scripts
- Reciprocal Rank Fusion (RRF) → introduced lexical noise between Tamil and English
These methods lacked sufficient semantic robustness for multilingual ranking tasks.
Key Insight
One of the most important findings from this work is: Multilingual RAG is not only a retrieval problem — it is also a ranking precision problem.
In practical systems:
- Retrieval ensures coverage
- Reranking ensures correctness
Without effective reranking, even strong retrievers can produce noisy or poorly ordered context for generation.
System Implementation at CTNLPR
At CTNLPR, this reranking architecture was integrated into our broader Tamil–English multilingual RAG pipeline as part of the ongoing Noolaham GPT initiative.
Our work included:
- Evaluating multilingual cross-encoder rerankers
- Benchmarking ranking quality using MRR and nDCG
- Designing CPU-efficient reranking pipelines
- Implementing ONNX-based optimized inference
- Reducing latency for real-world multilingual deployments
- Improving ranking stability across Tamil, English, and mixed-language queries
The final system now supports efficient, scalable, cross-lingual reranking for large multilingual document collections.
Conclusion
Reliable multilingual RAG systems require more than strong dense retrieval models. They require ranking-aware architectures capable of refining multilingual relevance before generation.
By combining:
- Dense retrieval
- Cross-encoder reranking
- CPU optimization techniques
- Quantized inference pipelines
we developed a scalable multilingual reranking system optimized for Tamil–English retrieval environments.