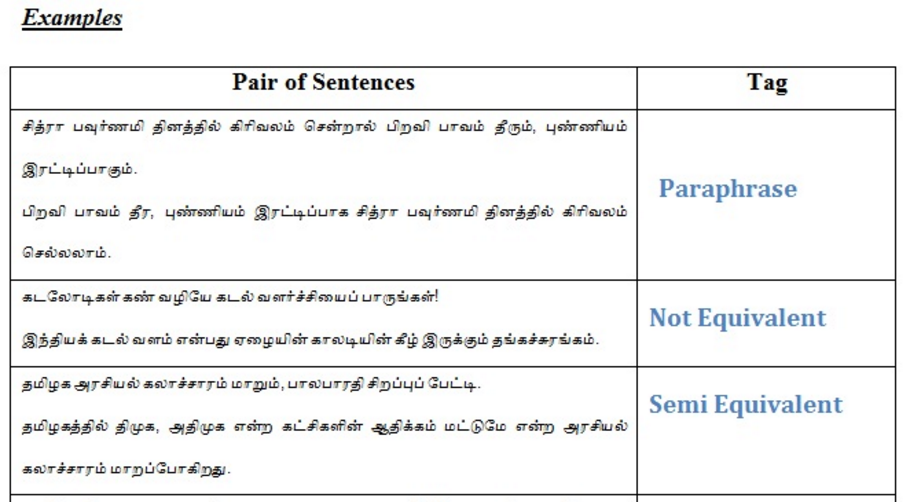
Summary: Paraphrase can be defined as “the same meaning of a sentence is expressed in another sentence using different words”. Paraphrases can be identified, generated or extracted. This project focuses on sentence level paraphrase identification for Tamil. Identifying paraphrases in Tamil is a difficult task, because evaluating the semantic similarity of the underlying content and the understanding the morphological variations of the language are more critical. Paraphrase identification is strongly connected with generation and extraction of paraphrases. The paraphrase identification systems improve the performance of a paraphrase generation in terms of choosing the best paraphrase candidate from the list of paraphrases candidates generated by paraphrases generation system. Paraphrase Identification is also used in validating the paraphrase extraction system and the machine translation system. In QA system, Paraphrase Identification plays a vital role in matching the questions asked by the user to the original questions for choosing the best answer. Plagiarism detection is another task which needs the Paraphrase Identification technique to detect the sentences which are paraphrases of others.
In this project the DPIL2016 dataset and a Tamil Monolingual Corpus will be used for training and testing. Tools and methodologies that would involve are Word2vec embedding, Shallow Parser – Tamil, RAE embedding and Logistic regression.
| Partner Institution | Center for Computational Engineering and Networking (CEN), Amrita Vishwa Vidyapeetham, Coimbatore, India |
| Supervisor | Dr. M. Anand Kumar |
| Research Students | Praveena R. |
| Source Code | https://github.com/ctnlpr/Paraphrase-Identification |